Procedural Spiral Mesh in Unity
Introduction
In visiting Washington State University's Webster Hall recently I came across an old infographic. It reminded me of similar ones I had seen as a child. Today as an adult with a design-eye, it resonates as a great way to communicate time-based relationships in a fairly compact space. I instantly wanted to make a modern version while taking the opportunity to improve some design decisions of the original designer(s).

Earth has been around
Spiral Mesh
I looked in Unity's Asset Store in hopes of finding a tool for creating the base spiral mesh that I needed. In experimenting with a few options, none managed to provide what I was after. This fact in combination with my backburnered desire to learn more about procedural mesh generation lead me to the creation of Spiral.cs and this article.
Though I still have a few additional components that I'm finalizing (which allow intelligent plotting along the spiral and are fucking cool), the base Spiral.cs for spiral mesh generation and manipulation is done. Here's what the Unity editor UI looks like with the Spiral component:

Spiral component FTW
To get a working spiral, all you have to do is:
- Create an empty
GameObject - Add a
Spiralcomponent
Easy right? By default there is no material applied, so feel free to update that in the associated and automatically created MeshRenderer.

Before

After
Spiral Options
There are six options for customizing your spiral mesh. You can manipulate them in the editor (in Edit or Play mode) or animate them in code during runtime. The six options are:
- Radius - radius of spiral
- Width - width of surface that follows the spiral's radius
- Height - height of the surface that follows the spiral's radius
- Length - length of the spiral
- Sides - curvature of spiral edges
- Offset - spacing between spiral revolutions
Below are the same options with visualized examples.
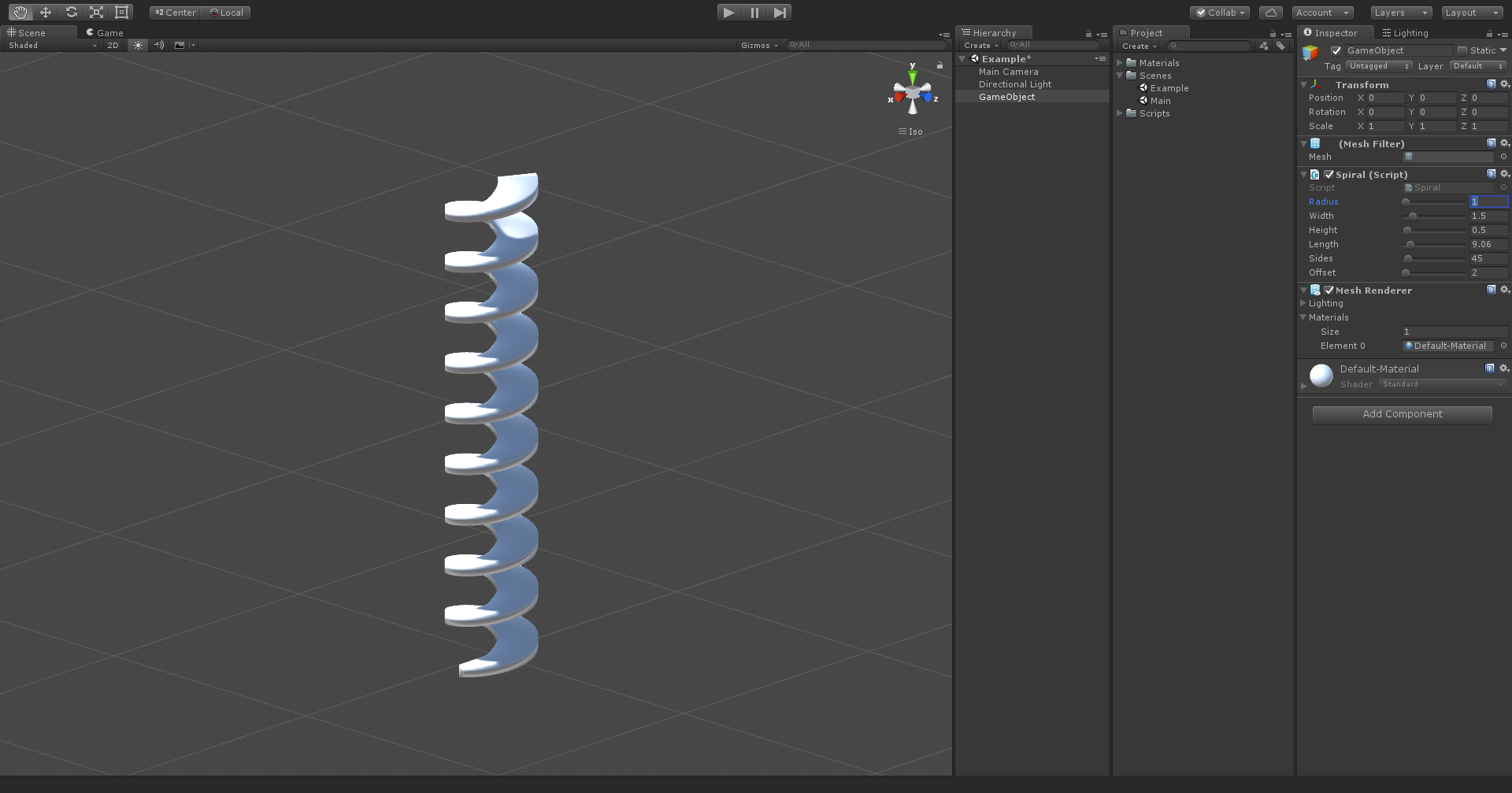
Low radius
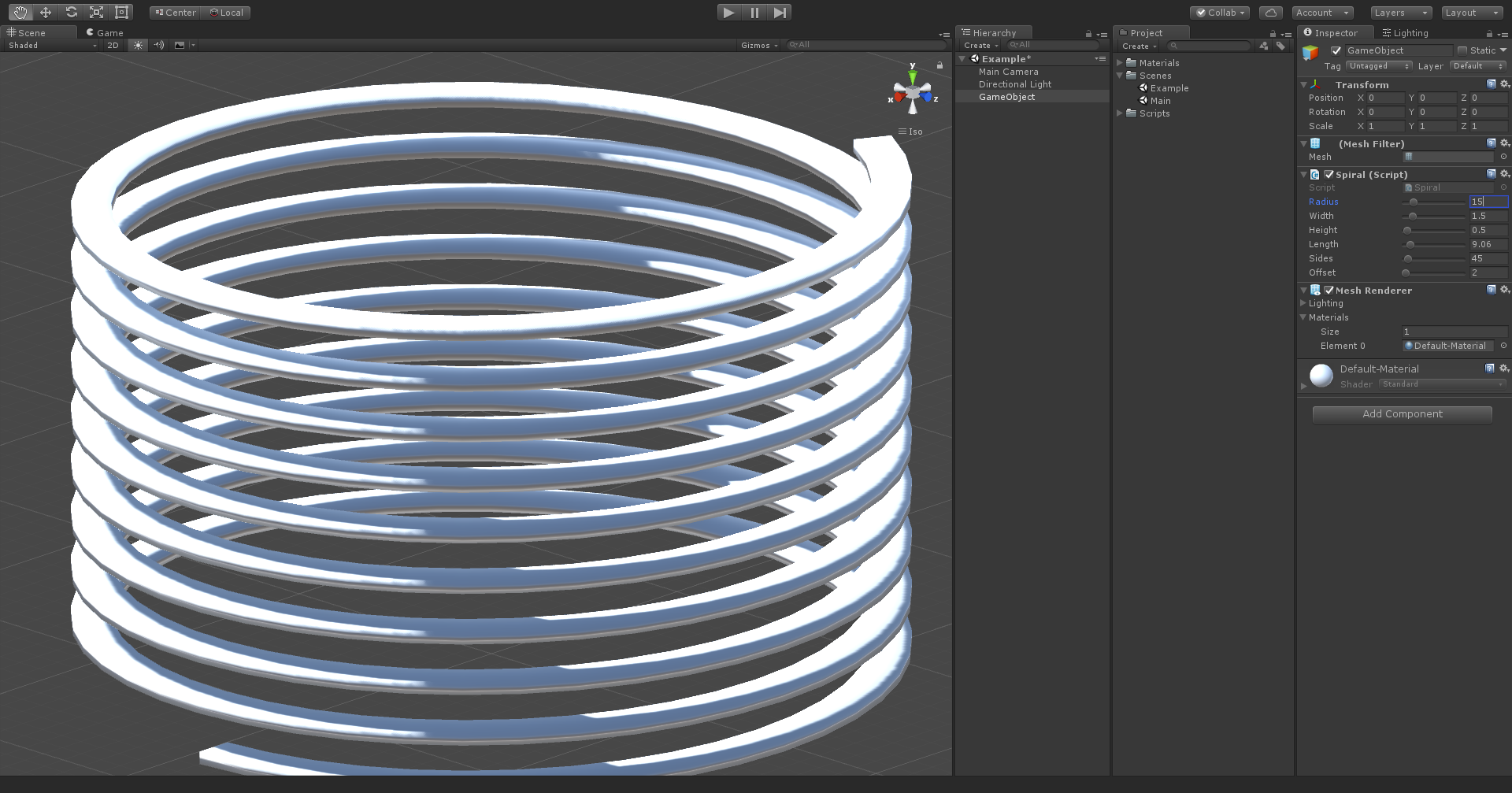
High radius

Low width

High width

Low height

High height

Low length

High length

Low sides

High sides
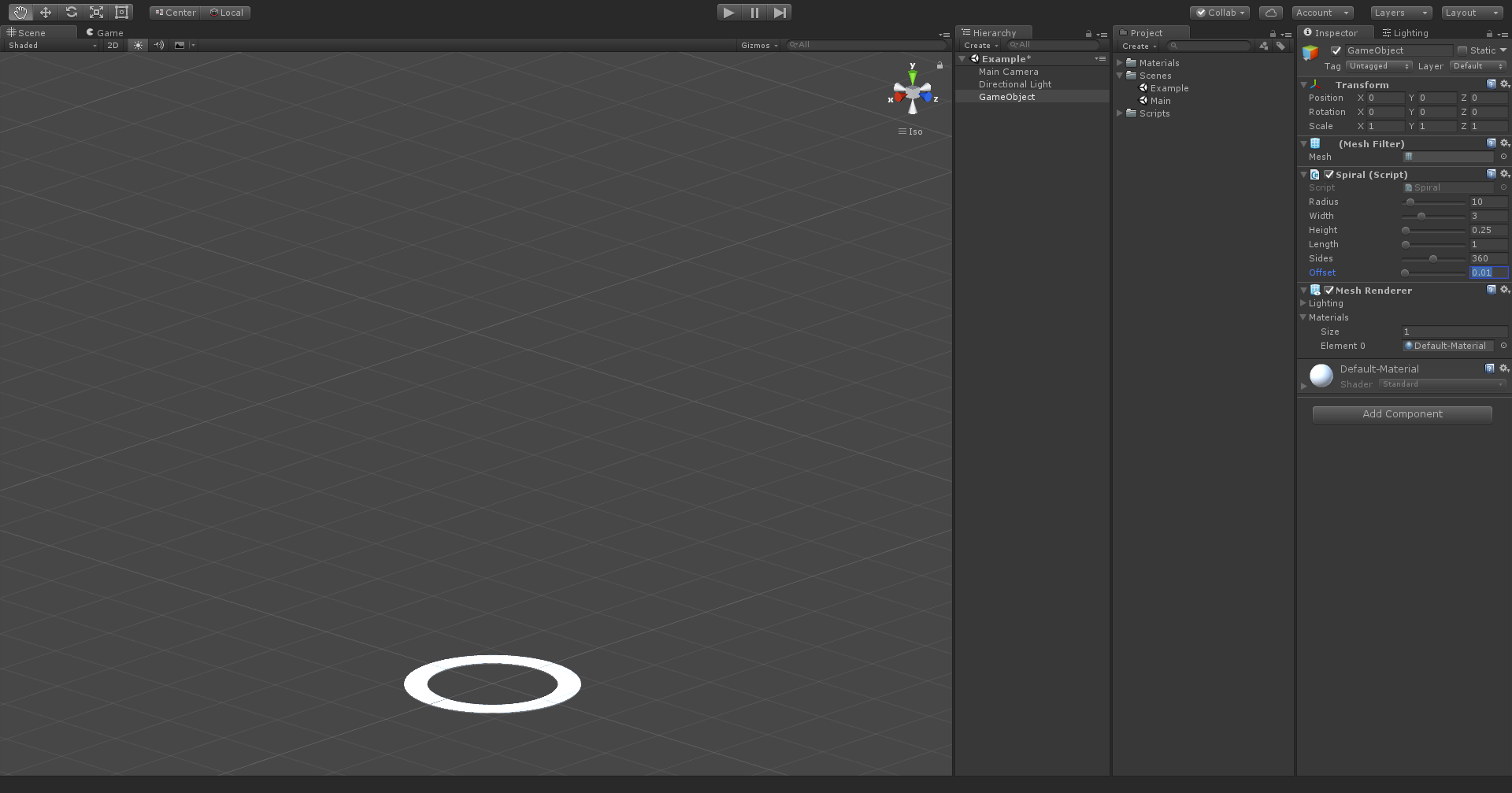
Low offset

High offset
If you end up using or forking Spiral.cs, don't hesitate to reach out on Twitter @derekknox and share what you are working on. Retweets are free. Get the source on GitLab.
Conclusion
I've backburnered making a port and PR for Three.js so feel free to take the source and do so 😊
Definitely BufferGeometry 😀
— mrdoob (@mrdoob) March 9, 2019