Neural Networks for Noobs
Purpose
The purpose of this article is to, without math or code, explain:
- what components exist within a neural net
- how those components fit together
- how a network learns
Introduction
A neural network, in the context of Machine Learning, is a biologically inspired coding approach that helps computers "learn". That sounds cool and magical, but complex too. Surprisingly however, neural networks are fundamentally quite simple.
Since computers work fast, learning can happen fast. This speed in addition to accuracy are what can make a neural network superior to humans in solving certain problems. A few examples where neural networks are used today include self-driving vehicles, processing in banking, address recognition by post offices, and in YouTube's recommendation engine.
The Components
There are surprisingly a small amount of components that comprise a neural network. In fact there are fundamentally just two. The power and complexity of a neural net relates directly to the type, interconnection, and number of these two components:
- artificial neuron
- neuron layer
The terms artificial neuron and neuron layer sound cool, but also slightly intimidating. Both are extremely simple however.
Artificial Neuron
An artificial neuron does three things:
- consumes input
- processes input
- produces output
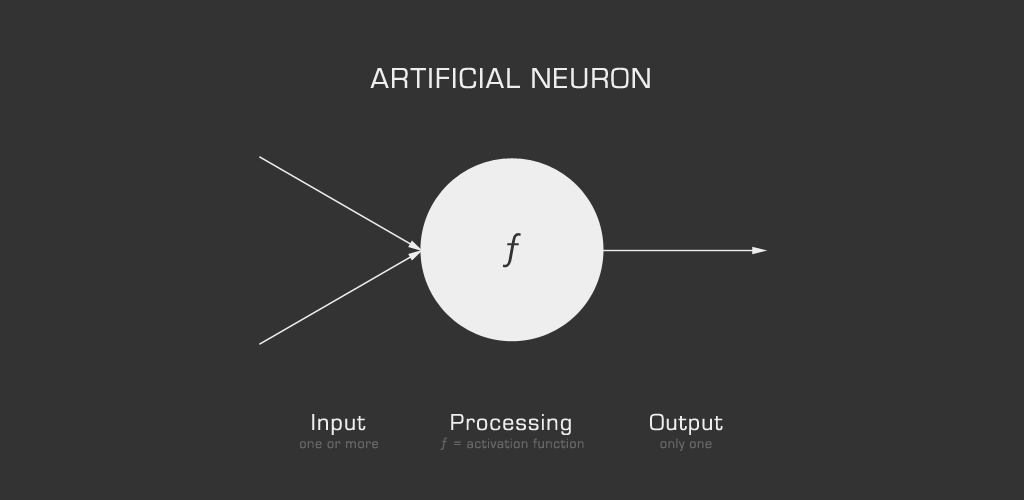
For those familiar with basic programming, each neuron is essentially a function that:
- consumes input (function arguments)
- processes input (function body - research activation functions to dig deeper)
- provides output (function return value)
You don’t need to know the details, but keep in the back of your mind the fact that each neuron’s consumes input step uses two additional values, a weight and a bias. This will be important in The Learning section below, so put that in your back pocket.
Neuron Layer
A neuron layer is simply a linear grouping of neurons, a list. For the those familiar with basic programming, this is just an array. Any number greater than zero is an acceptable neuron count for a given neuron layer. Super simple.
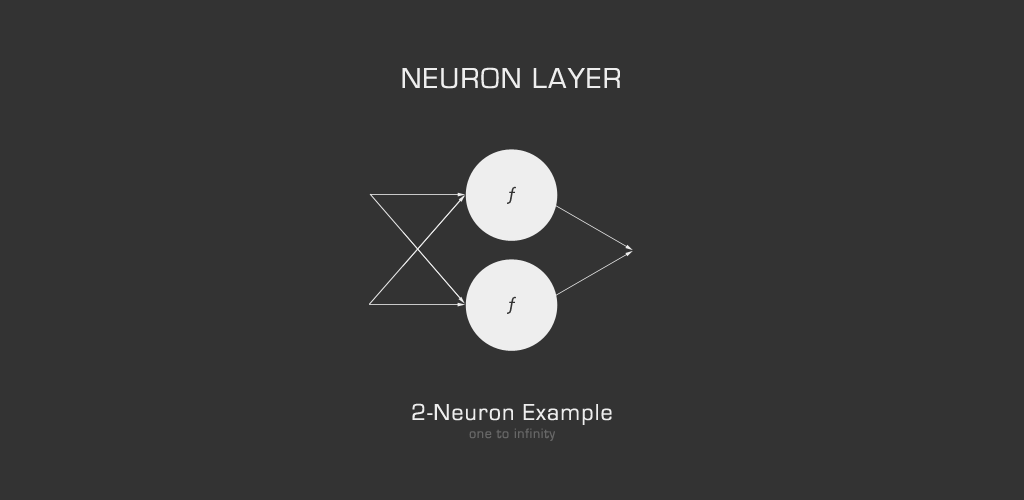
The Fit
Now that we know about neurons and layers, let's look into how they fit together to form a neural net. The anatomy of a neural net is composed of only three layer types:
- input layer
- hidden layer(s)
- output layer
Input Layer
The input layer can be thought of as a list of neurons that each only provide an output. They are the starting point for the neural net. For example, a neural net taking an image as input would map the data representing each pixel as an input value to the first hidden layer.
Hidden Layer(s)
The hidden layer(s) refer to the one or more neural layers, that’s it. Technically speaking, a net with one hidden layer refers to shallow learning whereas a net with two or more hidden layers refers to deep learning.
Neural net designers are still learning what designs work best for different problems. Generally speaking though, deep learning is better than shallow learning. This does not mean however that adding more hidden layers is always best. Just like doctors don’t have all the answers for fixing humans, neural net designers (in 2017 anyway) don’t know how best to fix nets. Shared best practices do exist and improve, but at its core, trial and error is still required when designing a net.
Output Layer
The output layer simply consumes as input, the last hidden layer’s output. All the neurons and their interconnections through the prior hidden layers results in a combined input consumed by the output layer. The output layer is responsible for processing the net as a whole and comparing the output against predetermined acceptable outputs.
The Learning
I mentioned earlier that neural nets are biologically inspired. Each designed neural net is simply a small computer program mimicking how the neurons in our brains transmit small signals (input > processing > output). As we saw in the components section above, this sounds more complicated than it actually is. What is complicated is understanding and managing the relationship between all the neurons and layers. This is where a computer can shine and ultimately makes them better than us in this regard.
There are two core phases a neural network goes through. Each phase is differentiated by its input data:
- training data ("learning")
- testing data ("testing")
Training Data
Training data is simply the data set (images of cats for example) that a neural net designer knows the correct output answers for and tells the program so it can tweak itself on the fly to learn. The designer then, through best practices and trial and error, tries to initialize settings for the small program (neuron type, neuron settings, neuron layer count, etc.) that leads the net to output correct answers.
When I said, tells the program so it can tweak itself on the fly to learn above, this is where the apparent magic of neural nets takes place. What essentially happens is this:
- The program is initialized with:
- designer determined settings (best practice and/or trial and error)
- random weight and bias values for each neuron (told you I’d come back to these)
- Each input (each pixel of each cat image) in the training data is looped over
- the output value of the net is compared to the known correct value resulting in an "error" value (research cost function to dig deeper)
- The program then tweaks the weight and/or bias values of neuron(s) in an effort to minimize this error value
So, the program can essentially manage the tweaking of specific neurons in specific hidden layers and compare how the error value changes through each loop iteration. The "learning" is really just trial and error on steroids at a pace we cannot keep up with. Pretty cool right.
After training is complete (the error rate is minimal), you can "save" the net by simply knowing what values to initialize the program with. Instead of setting up the weight and bias of each neuron to a random value, the “learned” values are instead used. This leaves you with a trained net that is ready for testing inputs it has never experienced before.
Testing Data
Since we’ve trained the neural net, we know the settings in addition to each neuron’s weight and bias values to initialize the program with. The next step is to simply provide new input data to the program and run it. If the net is robust, the "learned" values (settings for the program) will properly confirm or deny new input as valid (is it a cat image or not).
Conclusion
After training, each neuron has "learned" to understand a very small pattern. Understanding of each small pattern in totality often results in sophisticated pattern recognition. Once a net has been trained to where its error rate is very small (5% or less), its designer now has a small reusable program that may be an extremely powerful and/or lucrative tool. Think self-driving cars, superior medical diagnosis, manufacturing efficiencies, wide ranges of automation, and much more.